Model development and validation
The model was developed using supervised learning to solve the classification problem of non-compliance (0) or compliance (1).
To perform supervised learning, ComplianceCoach sources a dataset from production data to ensure there will be no discrepancy between the data used for training and the data used to serve real predictions. ComplianceCoach splits this dataset into three portions: train, validation and test. The model trains on a dataset that uses patient results with known compliance outcomes and “learns” to minimize errors between its predictions and known targets. Once trained, ComplianceCoach uses the validation dataset to estimate how well the model can generalize and predict when it uses new data. In addition, the validation dataset optimizes certain model parameters to improve performance. ComplianceCoach evaluates the model on a test dataset (unseen data) to verify how well it will perform in the real world and deploy the model after it can accurately predict results when it analyzes new data.
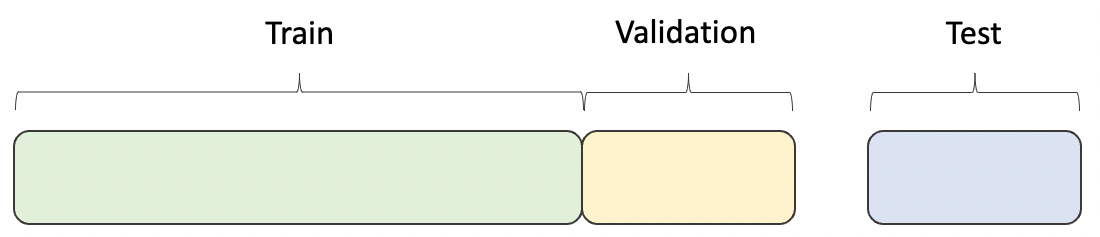 |
Visualization of the dataset splits
ComplianceCoach uses gradient-boosted decision trees—a standard, high-performance algorithm common in Machine-Learning applications—to create the 90-Day model. The algorithm uses the available data to make many small sequential decisions that inform and refine the larger compliance decision.
predict compliance probabilities that are lower than expected (false negatives) and probabilities higher than expected (false positives). However, the high accuracy, high AUC (0.9463) and low Brier (0.092) score demonstrate that the model generally performs well, and provides a useful HME tool to guide patient outreach.